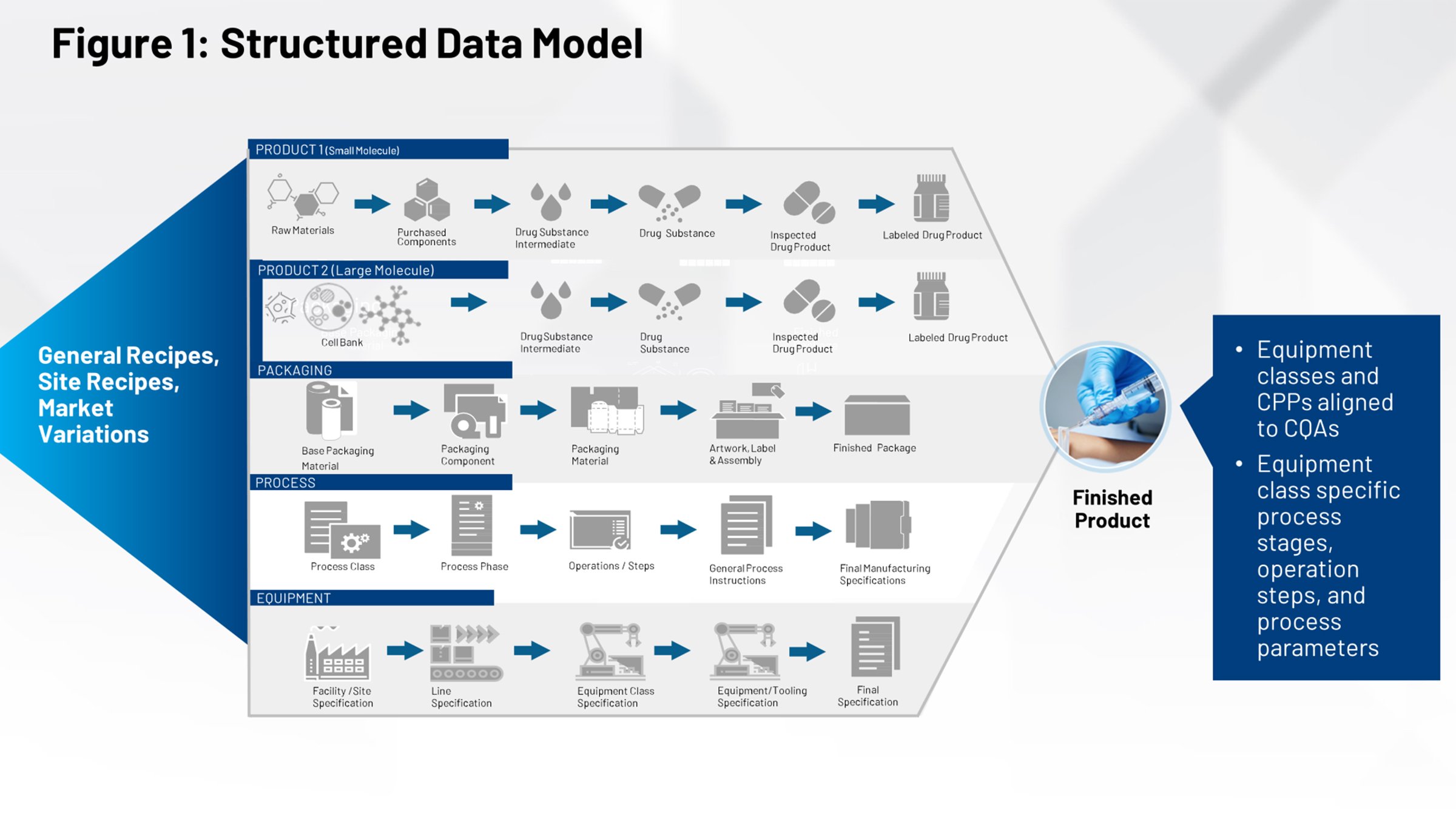
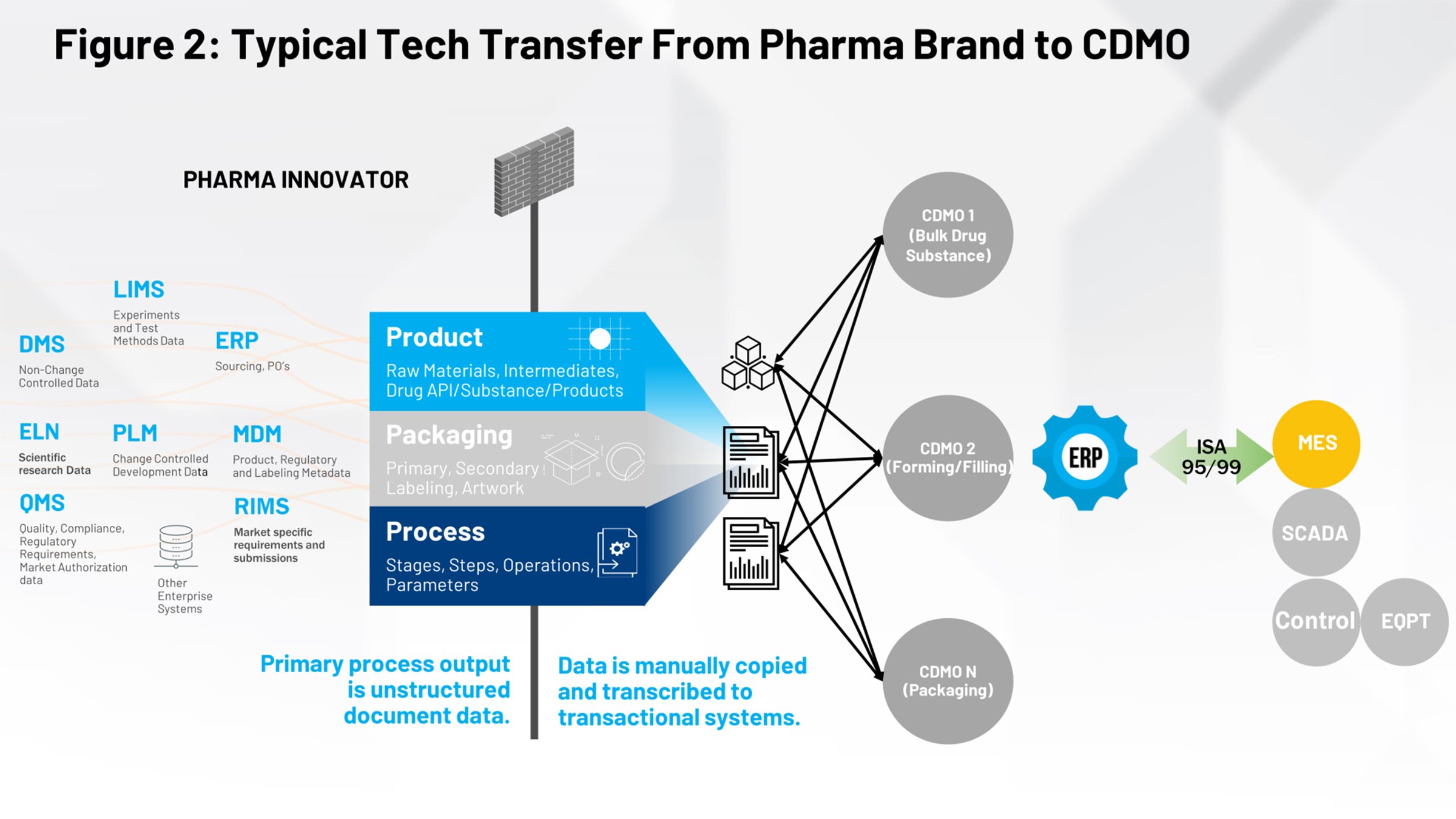
圖 2 呈現出生物科技產業的業內人士應該已經很熟悉的現行技術轉移過程。左側是所有有助於定義產品、包裝及製程的系統。這些資料均需要經過防火牆,再由內部製造群組或需要解讀與其有關之資訊的多個合約製造商接收。
我們的任務是要將這些電子文件或影像文件轉換成結構化且可重複的內容,讓我們可以持續提供給下游系統,並消除解讀文件意圖的人為因素。然後所有下游合作夥伴便能善用該資料。
如何做到
看看要達成這項任務的過程,首先我們必須確保提交的資料是安全的。許多公司都透過 FTP、電子郵件、電話及網站進行通訊,但從控制策略來說,保護智慧財產權 (IP) 是非常困難的。總之,技術轉移中流動的一切均為公司的 IP,且必須要確保其安全,並在適當的時間提供給合適的一方。
重點不僅是轉換資料;更重要是要追蹤資料。遇到不良事件時,您需要進行稽核追蹤,以便可以確切知道轉換的內容、核准人員、簽核人員、資料接收人員以及資料使用人員。
有些人會負責從科學家與製程開發工程師使用的不同系統收集所有資訊。然後他們必須將其整合成一份文件或文件概要,再安排將資料交付給製造單位的過程。
其中所缺少的是像 Google 翻譯這樣的編排與轉換機制,它能理解您要透過技術轉移溝通的真正意圖,並將其轉變成可預測與運用之內容。
其理念是,一旦將資料解析為可理解、重複使用的格式,下游系統便不再需要人力去輸入所有資訊。取而代之的是,資訊會自動推播到需要的系統中。
我們旨在運用一個能理解文件 (脈絡、語義、文法意圖) 的自然語言處理機制,以及一套能理解每份文件意圖的機器學習演算法,將其轉換成 ISA 88 結構化的格式。就本質上而言,其會取得文件並與數位資料整合,形成系統可以輕鬆接受且可重複使用的數位資料結構。
但技術轉移文件不僅僅包含表格或階層形式的數位或文字資料,還會有影像資料、色譜分析,以及取樣與測試方法。這些都是您無法輕易轉換成數位資料的非結構化資料集。但其會與某種層級的數位資料有關,因此您必須能理解文件中可能隱藏在不同資料集的內在差異。
當您透過自然語言處理工具處理該文件時,其可以拍攝掃描的影像,並用光學字元辨識 (OCR) 技術擷取資料。或者,如果其來源恰好是從 PDF 擷取出來的數位資料,則可以再次擷取資料。
此時,這個資料背後並無脈絡存在。工具單純將資料擷取出來,並說:「我理解文件中所存在的資料量。」 這個自然語言處理輸出會尋找關鍵指標,因此可建立表格化的資料集,以便下游系統能輕鬆匯入或接受。
這個方法的其中一項優點是能做到協作。當有數值被錯誤解讀時,與人協作處理 PDF 文件便非常困難。您要如何傳達? 您可能會寄電子郵件說:「嘿,第 22 頁第三段第四行有個數值我看不懂。」 若您可以將其擷取出來,情報層便能告訴您少了什麼,或是將您需要注意的地方標示出來,從而提高過程效率。
選擇一種途徑
有兩個方向能做到這點。其中一個是繼續做您正在做的,因為這是您認定的方法。在生物科技產業中,要推動改變非常困難。因此,您可以持續與開發單位合作,並讓他們繼續製作多年一直都在製作的相同 PDF 文件,再用自然語言處理層將其轉換成數位化且可再利用又易讀的內容。這是一種方法。
第二種途徑便是採用各種數位原生工具,讓您在開發過程前期對製程與原料進行建模,並原生發布數位資料集。我們很實際,因為我們知道生物科技產業某些領域可能要花數年 (甚至數十年) 才能採用原生數位解決方案。
在這段期間,我們正在推廣這兩種途徑:首先善用 AI 與機器學習的運算能力,將文件轉換成可重複使用的內容,然後再逐漸採用數位原生工具。其最大的優點就是單純的勞工效率,但還不僅如此:
- 加快臨床實驗、上市與市場授權 (產品變化或口味) 的速度
- 降低轉移到製造時,整體的內部與外部成本
- 提高製程驗證的速度與效率
- 降低設施、生產線與設備建置/啟動的延遲
- 提高批次品質,並減少廢料與報廢
- 改善法定送審與核准的速度
- 藉由依規範設計從開發到製造的過程,改善封閉迴路品質
- 提升對批次系列產品的追蹤能力 (正確的國家/地區,合適的產品)