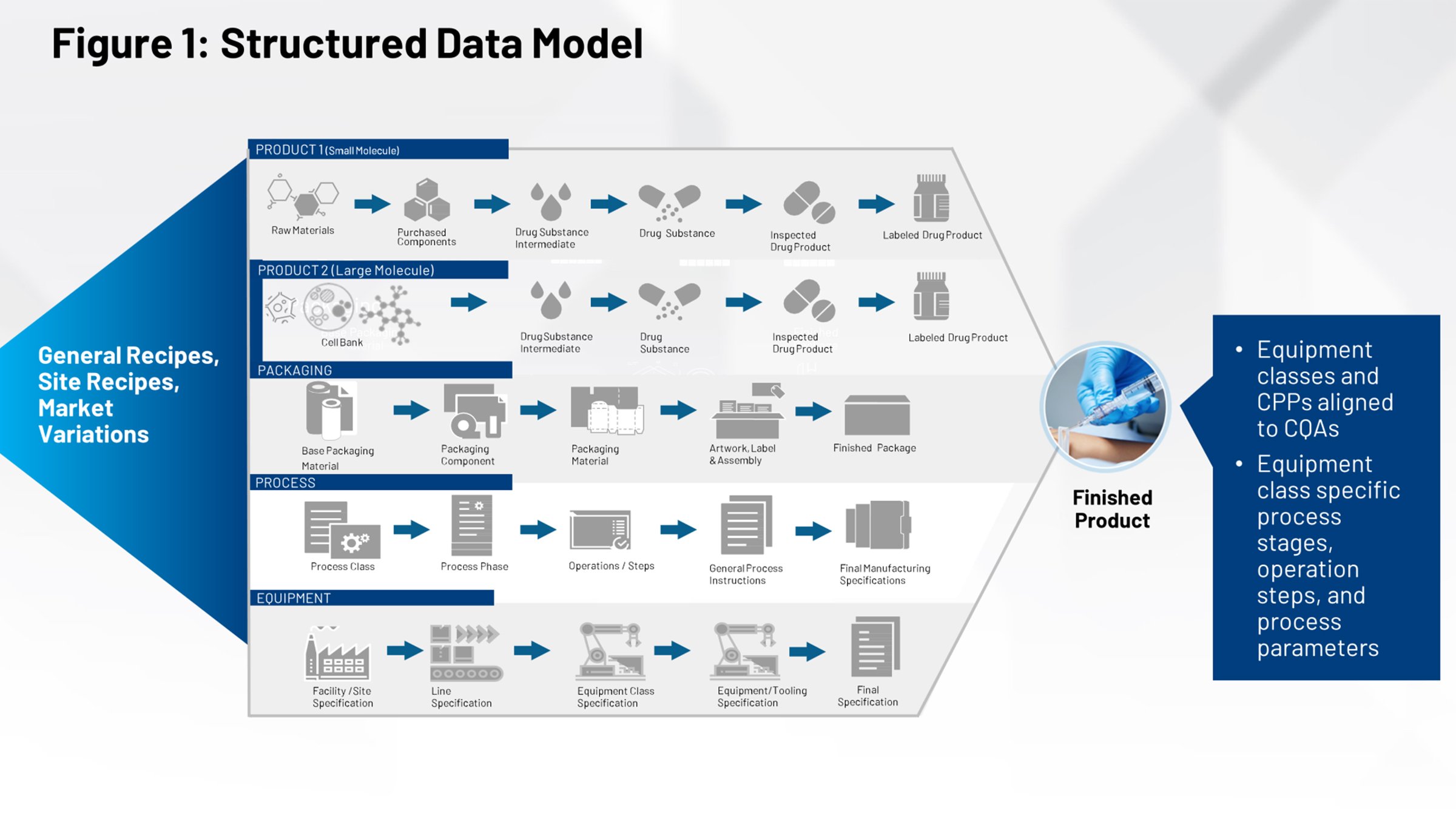
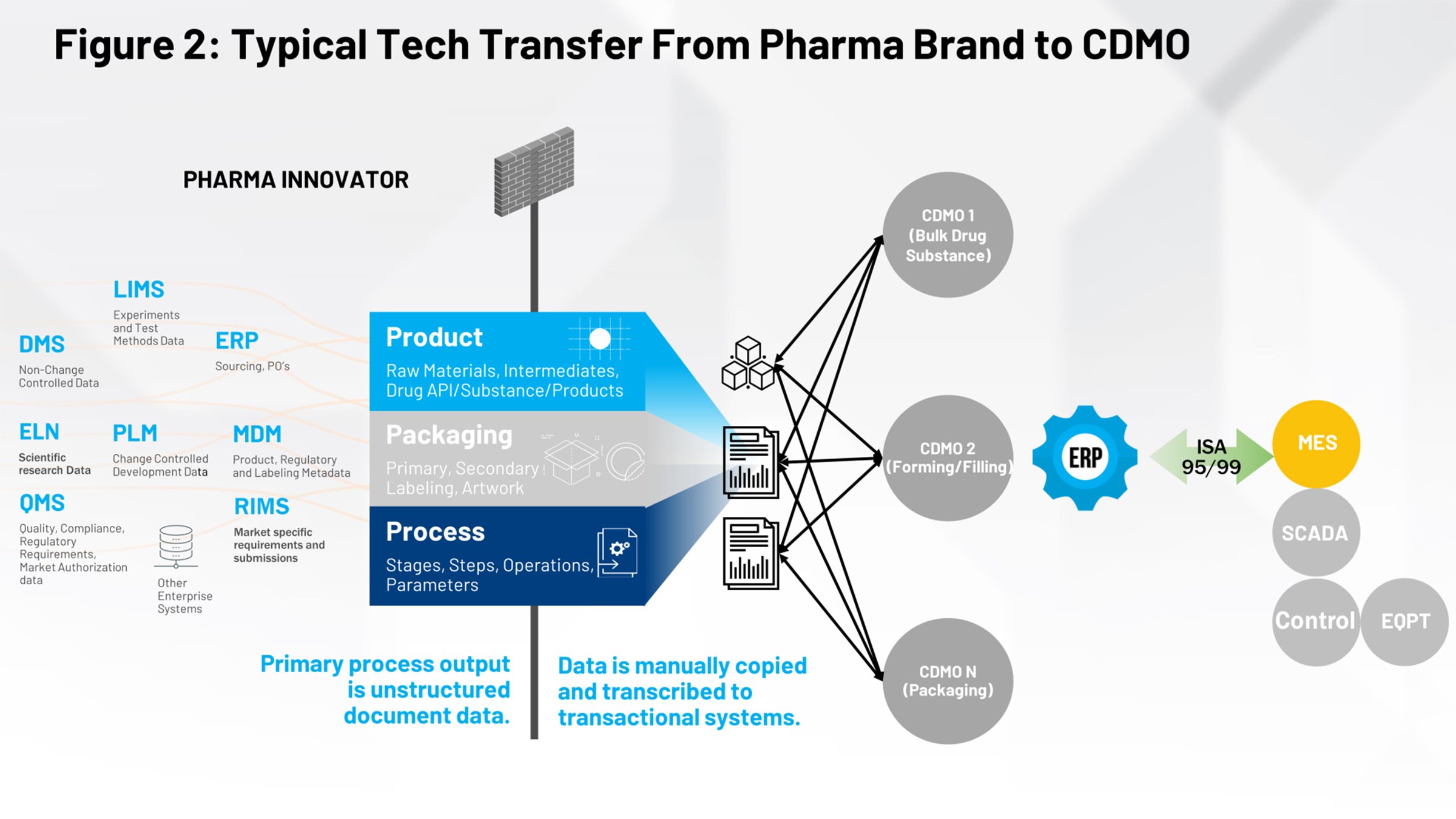
図2は、ライフサイエンス業界でよく知られる現在の技術移転プロセスを示しています。左側には、製品の定義、パッケージング、およびプロセスに携わるすべてのシステムがあります。これらの情報はすべてファイアウォールを通過し、関連する情報を理解する必要のある社内の製造グループまたは複数の契約製造業者が受け取る必要があります。
当社の使命は、これらの単にデジタル化しただけまたは画像ベースのドキュメントを、下流工程のシステムに一貫して提供できる構造化された再現可能なドキュメントに変換できるようにし、そのドキュメントの意図を解釈するプロセスから人的要素を取り除くことです。そうすることにより、下流工程のすべてのパートナがデータを活用できます。
その方法
この使命を達成するためのプロセスを見ると、まずデータがセキュアに送信されていることを確認する必要があります。多多くの企業はFTP、電子メール、電話、Webサイトを介して通信しており、制御戦略の観点から知的財産(IP)の保護が非常に困難になっています。結局のところ、技術移転を介して流れるものはすべて企業のIPであり、適切な関係者が適切なタイミングで保護して利用できるようにする必要があります。
データの変換だけではありません。また、そのデータを追跡することでもあります。有害事象が発生した場合の監査証跡が必要です。これにより、何が変換され、誰が承認し、誰が契約を締結し、誰がデータを受け取り、誰がデータを消費したかを正確に把握できます。
科学者やプロセス開発エンジニアが使用しているさまざまなシステムからすべての情報を収集するには責任者が存在します。次に、それを単一のドキュメントまたはドキュメントの概要に集約し、製造組織にデータを配信するプロセスを調整する必要があります。
欠けているのは、Google翻訳のような組織化と変換のメカニズムであり、技術移転を通じて伝えようとしていることの真の意図を理解し、それを予測可能で活用可能なものに変えることです。
考え方としては、データを理解可能で再利用可能な形式に構成すると、下流工程のシステムで人間がすべての情報を入力する必要がなくなるということです。かわりに、情報はそれを必要とするシステムに自動的に押し出されます。
目的はドキュメント(言葉の文脈、意味論、文法的な意図)を理解し、各ドキュメントの意図を理解してISA88構造化形式に変換できる機械学習アルゴリズムを備えた、自然言語処理メカニズムを使用することです。基本的に、ドキュメントを取得し、デジタルデータとつなぎ合わせて、システムが簡単に取り込むことができる再利用可能なデジタルデータ構造を作成します。
しかし技術移転文書には表や階層でフォーマットされたデジタルデータやテキストデータだけが含まれているわけではありません。画像データもあります。クロマトグラフィ分析もあるかもしれません。サンプリング方法とテスト方法があるかもしれません。これらはデジタルデータに簡単に変換できない非構造化データセットです。ただし、これらはデジタルデータのレベルにいくらか関連しているため、そのドキュメントに埋め込まれていると思われる各種データセット間の固有の違いを理解できる必要があります。
自然言語処理ツールを使用してドキュメントを実行すると、スキャンした画像を取得し、光学式文字認識(OCR)テクノロジを使用してデータを抽出できます。または元のデータがPDFドキュメントにキャプチャされたデジタルデータの場合は、データを再度引き出すことができます。
この時点では、このデータの背後に文脈はありません。ツールは単にデータを抽出し、このドキュメントに存在するデータの量を把握します。自然言語処理の出力では重要な指標を探すので、下流工程のシステムで簡単にインポートまたは取り込み可能な表形式のデータセットを作成できます。
このアプローチの利点の1つは、コラボレーションが可能になることです。値が誤って読取られると、PDFドキュメントで誰かと共同作業することは非常に困難です。どうやってそれを伝えるのでしょうか。あなたはメールを送って、「22ページの段落3の4行目に読めない値があります」と伝えます。それを抽出できれば、インテリジェンス層が不足しているものを教えてくれるか、注意を払う必要のある部分を強調表示して、プロセスをはるかに効率的にすることができます。
方法の選択
これには2つの方向があります。1つは、そのことを理解しているので、今日行なっていることを継続することです。ライフサイエンス業界では、変化を推進することは非常に困難です。そこで、開発組織との協力を継続し、開発組織が何年にもわたって作成したものと同じPDFを作成し、自然言語処理層を使用して、デジタルで再利用可能な読みやすいものに変換することができます。それが1つの方法です。
2つ目の方法は、開発プロセスの非常に早い段階でプロセスと資料をモデル化し、デジタルデータセットをネイティブに公開できるデジタル・ネイティブ・ツールを採用することです。私たちは現実的ですので、ライフサイエンス業界の特定の分野でネイティブ・デジタル・ソリューションを採用するには、数十年とまではいかなくても数年かかることがわかっています。
暫定的に、この2つの方法のアプローチを推進しています。AIと機械学習のコンピューティングパワーを使用して、ドキュメントを再利用可能なものに変換することから始め、その後、デジタル・ネイティブ・ツールを採用します。最大のメリットは純粋な労働効率ですが、それだけではありません。
- 治験、市場および市場承認(バリエーションまたは風味)までに要するスピードの向上
- 製造への内部および外部転送の全体的なコストの削減
- プロセス検証の速度と効率の向上
- 施設、ライン、機器のプロビジョニング/起動の遅延の短縮
- バッチ品質の向上、および廃棄物の削減
- 規制当局への申請・認可のスピードアップ
- 開発から製造、規制当局に至るまでの設計によるクローズドループ品質の向上
- バッチ系統へのトレーサビリティの向上(適切な国、適切な製品)