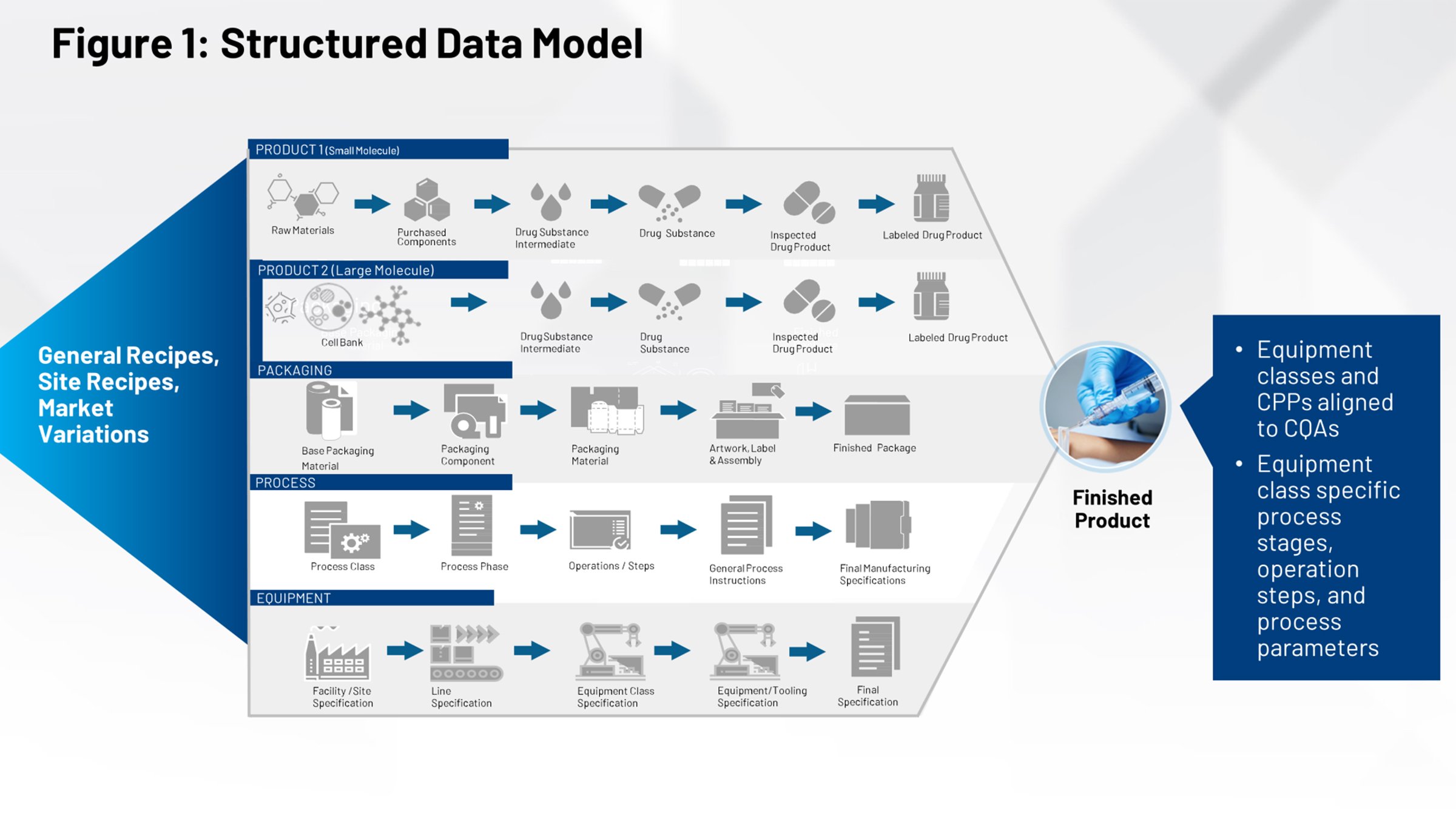
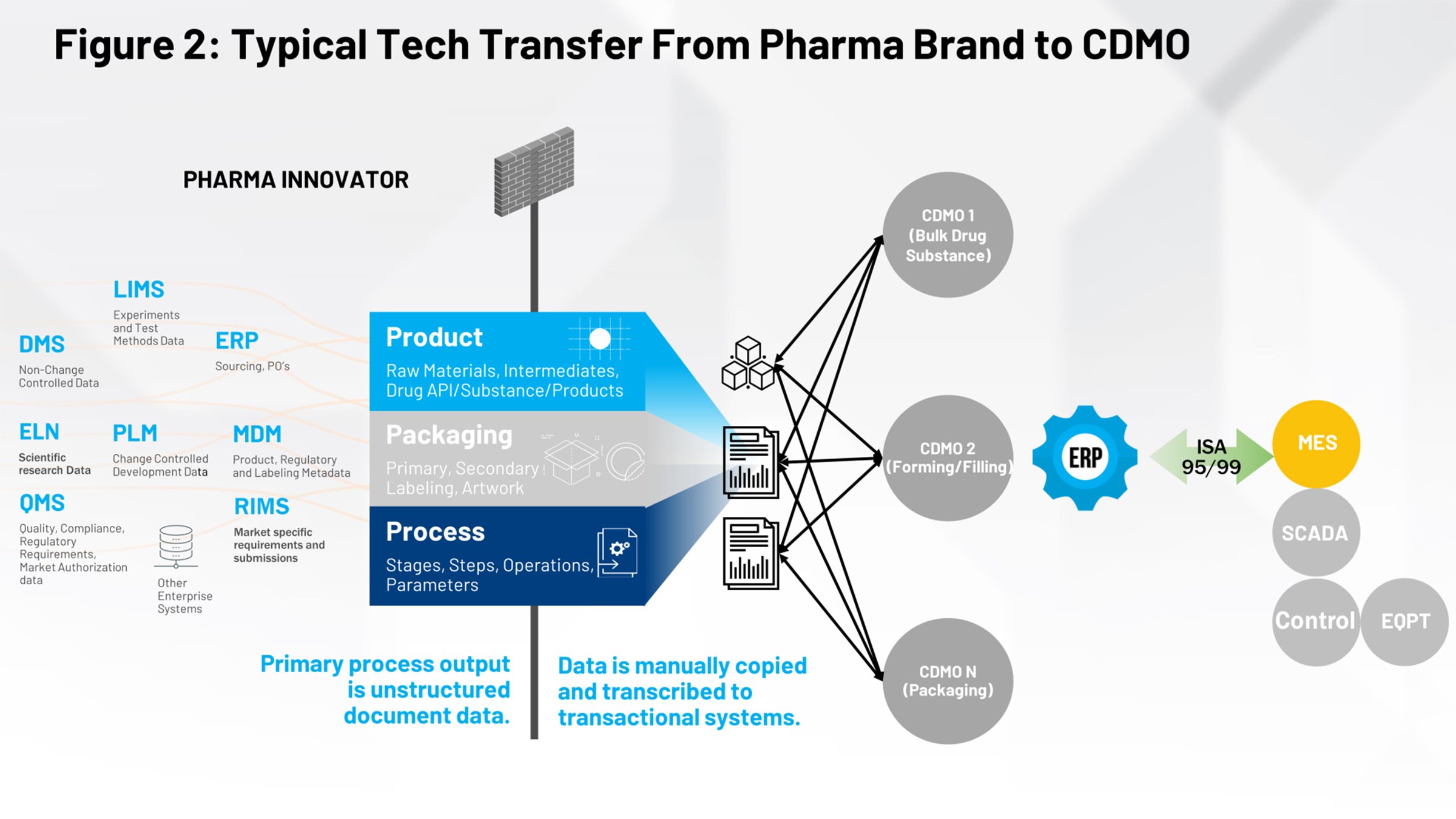
La Figura 2 illustra l’attuale processo di trasferimento tecnologico che dovrebbe essere familiare a chi opera nel settore delle scienze della vita. Sul lato sinistro sono presenti tutti i sistemi che contribuiscono alla definizione del prodotto, del packaging e del processo. Tutto ciò deve essere inviato attraverso un firewall e ricevuto da un gruppo di produzione interno o da più produttori a contratto che devono interpretare le informazioni rilevanti.
La nostra missione è quella di consentire la conversione di questi documenti "paper-on-glass" o basati su immagini in qualcosa di strutturato e ripetibile che possiamo fornire in modo coerente ai sistemi a valle, eliminando l’elemento umano di interpretazione del documento. A quel punto i dati possono essere utilizzati da tutti i partner a valle.
Come lo facciamo
Dobbiamo innanzitutto assicurarci che i dati siano inviati in modo sicuro. Molte aziende comunicano via FTP, e-mail, telefonate e siti web, e diventa molto difficile, dal punto di vista della strategia di controllo, proteggere la proprietà intellettuale (IP). In fin dei conti, tutto ciò che avviene attraverso un trasferimento tecnologico è proprietà intellettuale della vostra azienda, che deve essere protetta e resa disponibile alle persone giuste al momento giusto.
Non si tratta solo di convertire i dati, ma anche di tracciarli. È necessario prevedere un audit trail in caso di eventi avversi, in modo da poter capire esattamente cosa è stato convertito, chi lo ha approvato, chi lo ha firmato, chi ha ricevuto i dati e chi li ha usati.
Ci sono poi i responsabili della raccolta di tutte le informazioni provenienti dai diversi sistemi utilizzati dagli scienziati e dagli ingegneri addetti allo sviluppo dei processi. Essi devono aggregare tali informazioni in un singolo documento, o magari in una raccolta di documenti, e quindi gestire il processo di invio dei dati all’azienda di produzione.
Ciò che manca è quel meccanismo di gestione e conversione, come Google Translate, che comprenda il vero intento di ciò che si sta cercando di comunicare attraverso il trasferimento tecnologico e lo trasformi in qualcosa di prevedibile e sfruttabile.
L’idea è che una volta analizzati i dati in un formato comprensibile e riutilizzabile, i sistemi a valle non richiederanno agli operatori di inserire tutte le informazioni. Al contrario, le informazioni vengono inviate automaticamente al sistema che ne ha bisogno.
Il nostro intento è quello di utilizzare un meccanismo di elaborazione del linguaggio naturale che comprenda i documenti — il contesto delle parole, la semantica, l’intento grammaticale — e che disponga di un algoritmo di machine-learning in grado di comprendere l’intento di ciascun documento e di convertirlo in un formato strutturato ISA 88. In sostanza, si tratta di prendere i documenti e di unirli ai dati digitali per ottenere un costrutto di dati digitali riutilizzabili che i vostri sistemi possono recepire prontamente.
Ma i documenti di trasferimento tecnologico non contengono solo dati digitali o testuali formattati in tabelle o gerarchie. Contengono anche immagini. Potrebbero esserci analisi cromatografiche. Oppure metodi di campionamento e di analisi. Si tratta di set di dati non strutturati che non è possibile convertire facilmente in dati digitali. Ma sono correlati a dei dati digitali, per cui è necessario comprendere le differenze intrinseche tra i diversi set di dati che potrebbero essere nascosti in quel documento.
Lo strumento di elaborazione del linguaggio naturale, che analizza il documento, può rilevare le immagini scansionate e usare le tecnologie di riconoscimento ottico dei caratteri (OCR) per estrarre i dati. Oppure, se si tratta di dati digitali nativi che sono stati acquisiti in un documento PDF, è possibile estrarre nuovamente i dati.
A questo punto, non c’è alcun contesto dietro questi dati. Lo strumento ha semplicemente estratto i dati e ha comunicato: "Capisco il volume di dati che esiste in questo documento". L’output del sistema di elaborazione del linguaggio naturale cerca gli indicatori chiave in modo da poter creare set di dati tabellari che possono essere facilmente importati o acquisiti dal sistema a valle.
Uno dei vantaggi di questo approccio è la collaborazione che consente. È molto difficile collaborare con qualcuno su un documento PDF se un valore viene letto male. Come si fa a comunicarlo? Mandate un’e-mail e dite: "Guarda che a pagina 22, paragrafo tre, riga quattro, c’è un valore che non riesco a leggere". Se siete in grado di estrarre questi dati, il livello di analisi può dirvi cosa manca o evidenziare gli elementi a cui dovete prestare attenzione, in modo da rendere il processo molto più efficiente.
Scegliere un percorso
Ci sono due direzioni possibili. Una è quella di continuare a fare quello che state facendo oggi perché lo capite. Nel settore delle bioscienze, è molto difficile apportare cambiamenti. In questo modo potete continuare a lavorare con le aziende di sviluppo e far loro produrre gli stessi PDF che hanno prodotto per anni, e poi usare un sistema di elaborazione del linguaggio naturale per convertirli in qualcosa di digitale, riutilizzabile e leggibile. Questa è una possibilità.
La seconda strada consiste nell’adottare strumenti nativi digitali che consentono di modellare il processo e i materiali già nelle prime fasi del processo di sviluppo e di pubblicare in modo nativo i set di dati digitali. Siamo realisti e sappiamo che ci vorranno anni, se non decenni, prima che alcune aziende del Life Sciences adottino soluzioni native digitali.
Nel frattempo, promuoviamo questo approccio a due vie: iniziare a utilizzare la potenza di calcolo dell’intelligenza artificiale e del machine learning per convertire i documenti in qualcosa di riutilizzabile e poi, col tempo, adottare strumenti nativi digitali. Il vantaggio maggiore riguarda naturalmente l’efficienza lavorativa, ma non solo:
- Maggiore velocità dei clinical trial e di commercializzazione (varianti o tipologie)
- Riduzione del costo complessivo dei trasferimenti interni ed esterni alla produzione
- Maggiore velocità ed efficienza nella validazione dei processi
- Riduzione dei tempi di avvio di impianti, linee e apparecchiature
- Miglioramento della qualità dei lotti e riduzione degli scarti
- Maggiore velocità di approvazione normativa
- Miglioramento della qualità a ciclo chiuso, dallo sviluppo alla produzione e alla regolamentazione
- Migliore tracciabilità della genealogia dei lotti (paese giusto, prodotto giusto)