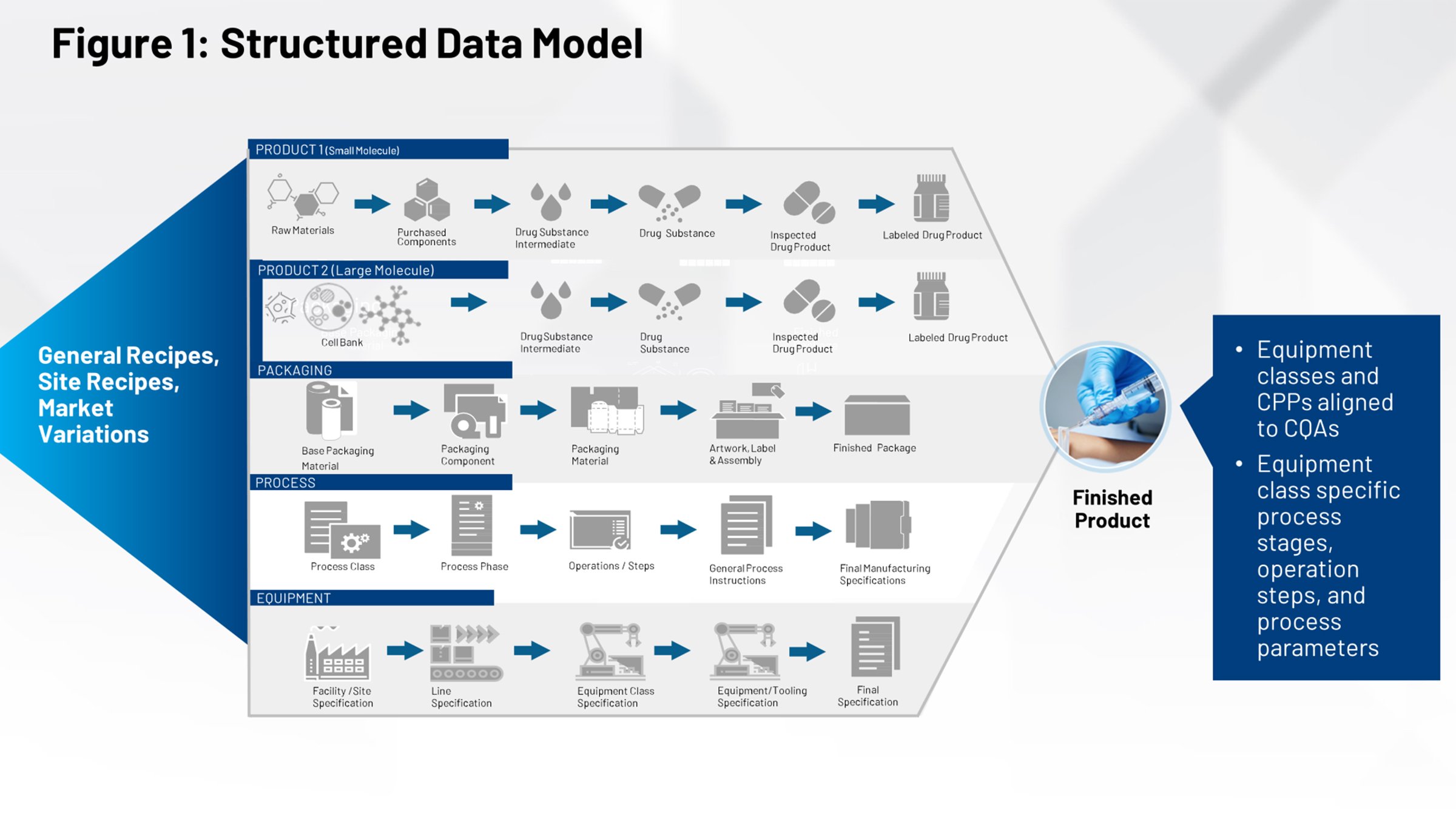
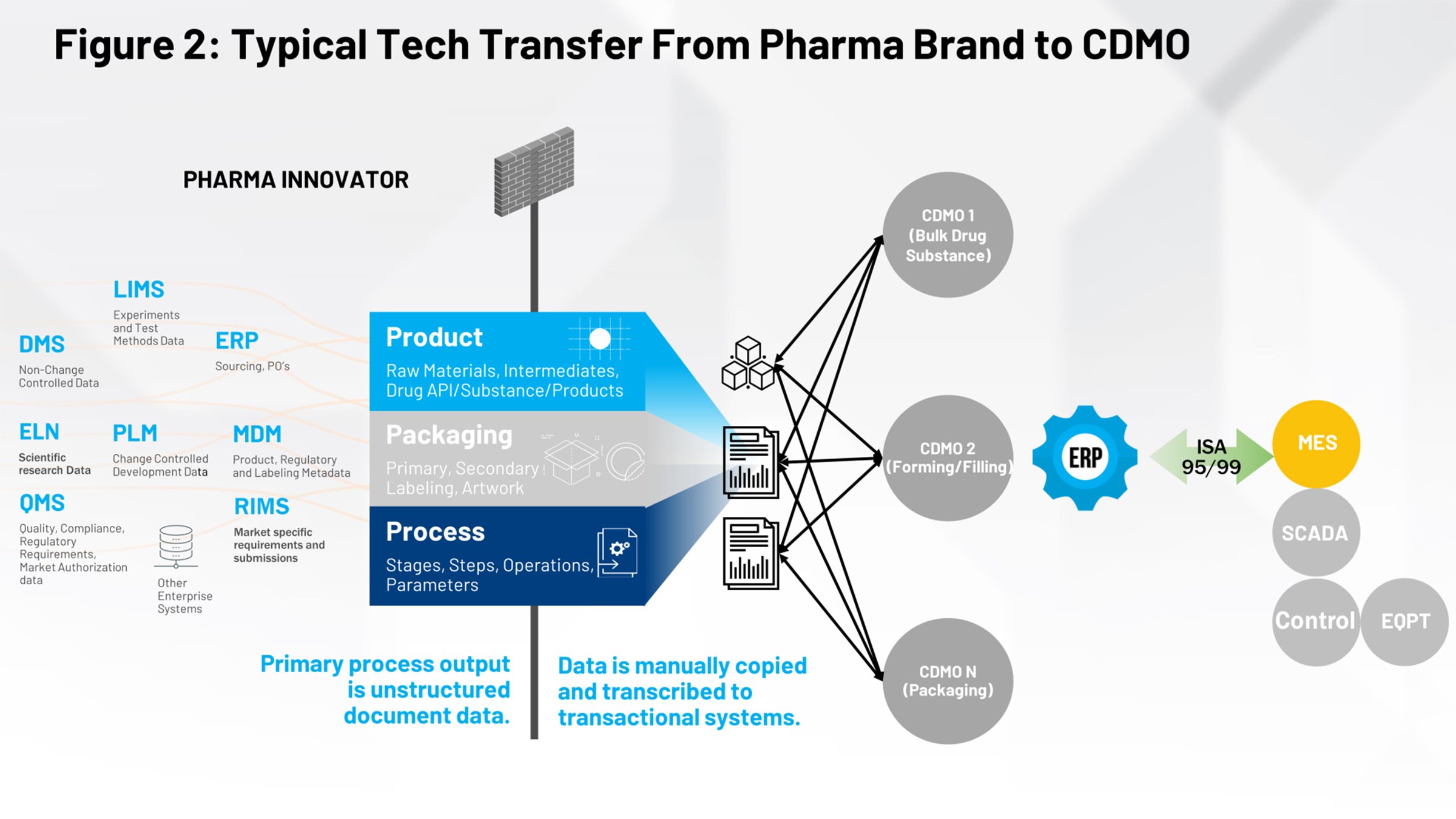
La figure 2 illustre le processus actuel de transfert technologique qui doit être familier à ceux qui travaillent dans le secteur des sciences de la vie. À gauche, vous avez tous les systèmes qui contribuent à la définition du produit, du conditionnement et du process. Tout cela doit être canalisé à travers un pare-feu et être réceptionné par un groupe de fabrication interne ou de multiples sous-traitants qui doivent interpréter correctement les informations qui les concernent.
Notre mission est de permettre la conversion de ces divers documents scannés ou à base d’images en un ensemble structuré et reproductible qui peut constamment alimenter les systèmes en aval et dont on a supprimé l’élément humain consistant à interpréter l’intention du document. Les données peuvent ensuite être exploitées par tous les partenaires en aval.
Comment procédons-nous ?
Pour accomplir cette mission, il nous faut tout d’abord veiller à ce que les données soient soumises en toute sécurité. Beaucoup d’entreprises communiquent via FTP, courriel, appels téléphoniques et sites Internet, si bien qu’il devient très difficile du point de vue d’une stratégie de contrôle de sécuriser la propriété intellectuelle. Au bout du compte, tout ce qui circule via le transfert technologique représente la propriété intellectuelle de votre entreprise, qui doit être sécurisée et mise à la disposition des bons partenaires au bon moment.
Il ne s’agit pas simplement de convertir les données ; il faut aussi les suivre. Il vous faut une piste d’audit pour savoir exactement, en cas d’événement malencontreux, ce qui a été converti, qui l’a approuvé et l’a validé, qui a reçu les données et qui les a consommées.
Quelqu’un est chargé de la collecte de toutes les informations provenant de tous les différents systèmes utilisés par les scientifiques et les ingénieurs en développement process. Ces informations doivent ensuite être agrégées en un seul document, ou peut-être un ensemble de documents, puis il faut orchestrer le processus de livraison des données à l’unité de fabrication.
Ce qui fait généralement défaut est ce mécanisme d’orchestration et de conversion tel qu’il est développé par Google Translate, qui maîtrise la véritable intention de ce que vous tentez de communiquer via le transfert technologique pour le transformer en quelque chose de prévisible et d’exploitable.
Une fois que les données sont transformées dans un format compréhensible et réutilisable, les systèmes à l’aval n’auront plus besoin de l’intervention humaine pour saisir toutes les informations. Au lieu de cela, l’information est automatiquement transmise au système qui en a besoin.
Notre but est d’utiliser un mécanisme de traitement par langage naturel pour comprendre les documents — le contexte du vocabulaire, la sémantique des mots, l’intention grammaticale — et de faire appel à un algorithme d’apprentissage automatique qui assimile l’intention de chaque document et la convertit en un format structuré ISA 88. Concrètement, le processus consiste à prendre les documents et les coller les uns aux autres avec des données numériques, ce qui aboutit à une construction réutilisable de données numériques, facilement consommables par vos systèmes.
Mais les documents de transfert technologique n’ont pas simplement des données numériques ou textuelles, formatées en tableau ou hiérarchisées. Ils ont aussi des données sous forme d’images. Il peut s’agir d’analyses chromatographiques. Ou de méthodes d’échantillonnage et d’essai. Il s’agit d’ensembles de données non structurés que vous ne pouvez pas aisément convertir en données numériques. Ces ensembles sont néanmoins quelque peu liés à une forme de données numériques, il faut donc pouvoir discerner les différences inhérentes entre les différents ensembles de données enfouies dans le document.
Lorsque vous traitez le document par le langage naturel, l’outil utilisé prend les images scannées et fait appel aux technologies de reconnaissance optique de caractères (OCR) pour en extraire les données. Ou, si le document PDF provient à l’origine de données numériques, l’outil de traitement rétablit ces données.
À ce stade, les données ne sont pas contextualisées. L’outil a simplement extrait les données et il ne fait que constater le volume de données dans le document. La sortie du traitement par le langage naturel recherche des indicateurs clés de manière à pouvoir créer des ensembles de données en tableaux, facilement importables ou consommables par le système en aval.
L’un des avantages de cette approche est la collaboration qu’elle rend possible. Il est très difficile de collaborer avec quelqu’un sur un document PDF si une valeur est mal lue. Comment exprimer cela ? Vous envoyez un courriel disant : « Bonjour, à la page 22, au paragraphe 3, je ne parviens pas à lire une valeur sur la ligne 4 ». Si vous pouvez l’extraire, la couche d’intelligence vous explique ce qui est manquant ou souligne les passages auxquels prêter attention de sorte que vous rendez le processus beaucoup plus efficace.
Choisir une voie
Il existe deux directions possibles. L’une consiste à ne rien changer parce que vous maîtrisez ce que vous faites. Dans le secteur des sciences de la vie, c’est très difficile d’inciter au changement. Vous pouvez ainsi continuer à travailler avec les entreprises de développement et leur confier la production des mêmes documents PDF qu’ils produisent depuis des années, puis faire appel à un traitement par langage naturel pour les convertir en éléments numériques réutilisables et lisibles. C’est une voie possible.
La seconde voie consiste à adopter des outils nativement numériques qui vous permettent de modéliser le process et les matières très tôt dans le processus de développement et de publier nativement les ensembles de données numériques. Nous sommes réalistes et savons que cela prendra des années — voire des décennies — pour que certains domaines du secteur des sciences de la vie adoptent des solutions nativement numériques.
C’est pour cela qu’entre-temps, nous encourageons cette approche bidirectionnelle : démarrer par l’utilisation de la puissance de traitement de l’AI et de l’apprentissage automatique pour convertir les documents en éléments réutilisables, puis au fil du temps, adopter des outils nativement numériques. Le plus gros avantage est l’amélioration de la productivité, mais pas seulement :
- Accélération des essais cliniques, des autorisations de mise sur le marché (variantes) et de la commercialisation
- Réduction du coût global des transferts internes et externes vers la production
- Accélération et plus grande efficacité de la validation des process
- Diminution de la latence du dimensionnement/démarrage de l’usine, des lignes et des équipements de production
- Amélioration de la qualité des lots et réduction des déchets et rebuts
- Accélération des soumissions et approbations réglementaires
- Amélioration de la boucle du concept qualité, du développement à la fabrication, en passant par la conformité
- Amélioration de la traçabilité dans la généalogie des lots (pays approprié, produit approprié)