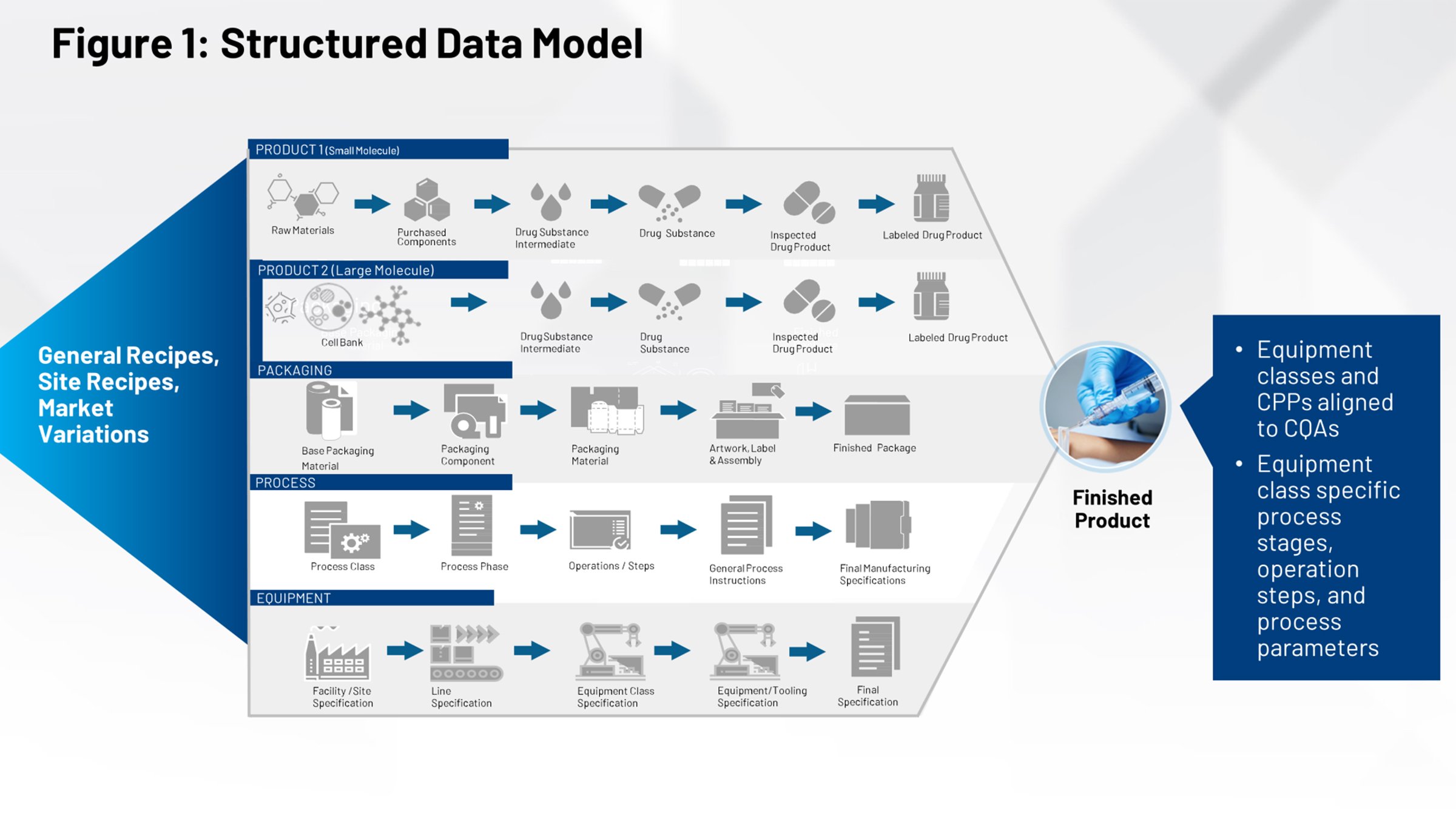
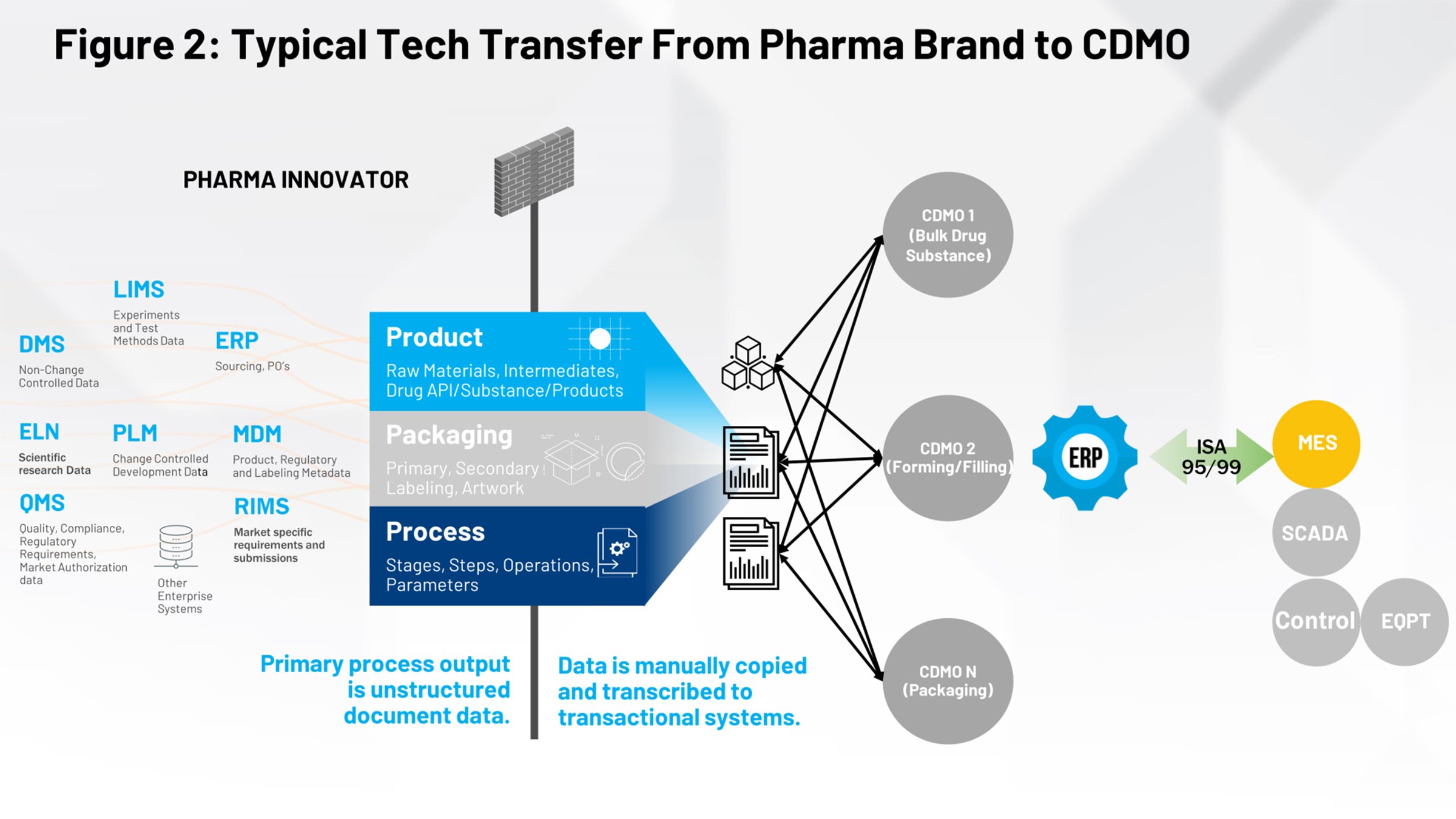
Abbildung 2 veranschaulicht den derzeitigen Prozess des Technologietransfers, der denjenigen von uns, die in der Life-Sciences-Branche tätig sind, vertraut sein sollte. Auf der linken Seite finden Sie alle Systeme, die zur Definition des Produkts, der Verpackung und des Prozesses beitragen. All diese Daten müssen durch eine Firewall geleitet werden und entweder von einer internen Fertigungsgruppe oder von mehreren Vertragsherstellern empfangen werden, die die für sie relevanten Informationen interpretieren müssen.
Unsere Aufgabe ist es, die Konvertierung dieser „Paper-on-Glass“- oder bildbasierten Dokumente in etwas Strukturiertes und Wiederholbares zu ermöglichen, das wir nachgelagerten Systemen konsistent zur Verfügung stellen können, und den Faktor Mensch aus der Interpretation der Absicht des Dokuments herauszunehmen. Anschließend können die Daten von allen nachgelagerten Partnern genutzt werden.
Realisierung
Beim Betrachten des Prozesses zur Erfüllung dieser Aufgabe müssen wir zunächst sicherstellen, dass die Daten sicher übermittelt werden. Viele Unternehmen kommunizieren über FTP, E-Mail, Telefonanrufe und Websites, und aus Sicht der Kontrollstrategie wird es sehr schwierig, geistiges Eigentum zu schützen. Letztendlich gehört alles rund um den Technologietransfer zum geistigen Eigentum Ihres Unternehmens, das gesichert und den richtigen Parteien zum richtigen Zeitpunkt zur Verfügung gestellt werden muss.
Dabei geht es nicht nur um die Umwandlung der Daten, sondern auch um deren Nachverfolgung. Es muss ein Audit Trail für den Fall eines unerwünschten Ereignisses vorhanden sein, damit Sie genau nachvollziehen können, was konvertiert wurde, wer dies genehmigt hat, wer es abgezeichnet hat, wer die Daten erhalten und wer sie genutzt hat.
Jemand ist dafür verantwortlich, alle Informationen aus den verschiedenen Systemen zu erfassen, die von den Wissenschaftlern und Prozessentwicklern verwendet werden. Dann müssen die Daten in einem einzigen Dokument oder gar in einem Kompendium von Dokumenten zusammengefasst werden und der Prozess, mit dem die Daten der Fertigungsorganisation bereitgestellt werden, muss orchestriert werden.
Was fehlt, ist ein Orchestrierungs- und Konvertierungsmechanismus wie Google Translate, der die wahre Absicht dessen, was durch den Technologietransfer kommuniziert werden soll, versteht und in etwas Vorhersehbares und Verwertbares umwandelt.
Es geht darum, die Daten in ein verständliches, wiederverwendbares Format umzuwandeln, damit die Informationen nicht mehr durch den Menschen erneut eingegeben werden müssen. Stattdessen werden die Informationen automatisch an das System weitergeleitet, das sie benötigt.
Wir beabsichtigen, einen Mechanismus zur Verarbeitung natürlicher Sprache zu verwenden, der die Dokumente versteht – den Kontext der Wörter, die Semantik, die grammatikalische Absicht – und über einen Algorithmus für maschinelles Lernen verfügt, der die Absicht jedes Dokuments verstehen und es in ein strukturiertes ISA 88-Format umwandeln kann. Im Grunde genommen werden die Dokumente mit digitalen Daten verknüpft, um ein wiederverwendbares digitales Datenkonstrukt zu schaffen, das Ihre Systeme problemlos verarbeiten können.
Doch Technologietransferdokumente bestehen nicht nur aus digitalen oder Textdaten, die in Tabellen oder Hierarchien formatiert sind. Sie umfassen auch Bilddaten. Möglicherweise liegt eine Chromatographieanalyse vor. Es könnte Probenahmeverfahren und Testmethoden geben. Dabei handelt es sich um unstrukturierte Datensätze, die sich nicht ohne Weiteres in digitale Daten umwandeln lassen. Sie beziehen sich jedoch auf eine bestimmte Ebene digitaler Daten, sodass man in der Lage sein muss, die inhärenten Unterschiede zwischen den verschiedenen Datensätzen zu verstehen, die in diesem Dokument enthalten sein könnten.
Wenn Sie das Dokument mit dem Tool für die Verarbeitung natürlicher Sprache verarbeiten, kann es aus gescannten Bildern mithilfe von Technologien zur optischen Zeichenerkennung (Optical Character Recognition, OCR) Daten extrahieren. Oder, wenn Daten digitalen Ursprungs sind, die in einem PDF-Dokument erfasst wurden, können die Daten wieder herausgezogen werden.
Zu diesem Zeitpunkt liegen diese Daten ohne Kontext vor. Das Tool hat lediglich die Daten extrahiert und gesagt: „Ich verstehe die Datenmenge, die in diesem Dokument vorliegt.“ Bei der Verarbeitung natürlicher Sprache wird nach Schlüsselindikatoren gesucht, sodass tabellarische Datensätze erstellt werden können, die sich leicht importieren oder in das nachgelagerte System einlesen lassen.
Einer der Vorteile dieses Ansatzes ist die Zusammenarbeit, die dadurch möglich wird. Es ist nahezu unmöglich, mit jemandem auf der Grundlage eines PDF-Dokuments zusammenzuarbeiten, wenn ein Wert falsch eingelesen wird. Wie kann das vermittelt werden? Sie versenden eine E-Mail und sagen: „Hey, auf Seite 22, Absatz drei, Zeile vier steht ein Wert, den ich nicht lesen kann“. Wenn Sie in der Lage sind, diese Informationen zu extrahieren, kann die Intelligenzebene Ihnen aufzeigen, was fehlt, oder die Elemente hervorheben, auf die Sie achten sollten, damit Sie den Prozess wesentlich effizienter gestalten können.
Welchen Weg möchten Sie gehen?
Sie können zwei Richtungen einschlagen: Entweder Sie machen so weiter wie bisher, weil Sie mit der Vorgehensweise vertraut sind. In der Life-Sciences-Branche ist es sehr schwer, den Wandel voranzutreiben. Sie können also weiterhin mit Entwicklungsorganisationen zusammenarbeiten und sie dieselben PDF-Dateien erstellen lassen, die diese schon seit Jahren erstellen, und dann diese Dokumente mithilfe einer Ebene zur Verarbeitung natürlicher Sprache in etwas Digitales, Wiederverwendbares und Lesbares umzuwandeln. Das ist die eine Möglichkeit.
Alternativ können Sie digitale, native Tools einsetzen, mit denen Sie den Prozess und die Materialien sehr früh im Entwicklungsprozess modellieren und die digitalen Datensätze nativ veröffentlichen können. Wir sind realistisch, denn wir wissen, dass es Jahre – wenn nicht sogar Jahrzehnte – dauern wird, bis bestimmte Bereiche der Life-Sciences-Branche native digitale Lösungen einführen werden.
In der Zwischenzeit fördern wir diesen Ansatz mit den zwei Wegen: Beginnen Sie damit, die Rechenleistung von KI und maschinellem Lernen zu nutzen, um Dokumente in etwas Wiederverwendbares umzuwandeln, und stellen Sie dann im Laufe der Zeit auf digitale native Tools um. Der größte Vorteil ist die reine Arbeitseffizienz, aber es gibt weitere Vorteile:
- Beschleunigte klinische Studien, Markteinführungen und Marktzulassungen (Varianten oder Geschmacksrichtungen)
- Geringere Gesamtkosten für interne und externe Übertragungen in die Fertigung
- Schnellere und effizientere Prozessvalidierung
- Geringere Latenzzeit bei der Bereitstellung/Inbetriebnahme von Einrichtungen, Linien und Anlagen
- Verbesserte Chargenqualität sowie weniger Ausschuss und Abfall
- Schnellere Einreichung und Genehmigung von Zulassungsanträgen
- Verbesserter geschlossener Qualitätskreislauf von der Entwicklung über die Herstellung bis hin zur Zulassung
- Verbesserte Rückverfolgbarkeit der Chargengenealogie (richtiges Land, richtiges Produkt)